
Neo4j Graph Database RAG
Answer questions using information stored in a graph


Neo4j is an enterprise grade database that has native storage for graphs with nodes and edges that is optimized for node traversal. In this article we will go through:
Neo4j terminology
Running Neo4j
Load an example movie graph
RAG with a graph
Strengths
Weaknesses
Resources
You can skip the “Running Neo4j” and “Load an example graph” sections if you don’t plan on running the examples code linked in the resources.
Neo4j terminology
Neo4j has with a specific set of terminology related to graph data structures. The most important terms include:
Node - Nodes are typically nouns. A node might represent a single actor or movie. Nodes can have labels and properties.
Relationship - Relationships make up the edges of the graph and connect nodes together. Relationships have a direction and a type. They can also have labels and properties like nodes. For example, a relationship with type “ACTED_IN” could connect a person to a movie.
Label - Labels can be used to group nodes and relationships. Examples of labels are Movie and Person.
Property - A property provides meta data about a node or relationship. An actor might have a name and a movie might have a release date
Cypher - Cypher is a specialized query language used to query and traverse graphs. A Cypher query returns data in the form of graphs and tables
Running Neo4j
The are a number of ways to run Neo4j including a cloud based deployment called Aura, local deployments through native servers and container based options. This article will assume a Docker deployment. We can launch Neo4j by issuing the following docker command.

We need to include the apoc plugin (a library of common procedures) because the python packages used in the example code rely on functionality from this plugin. This command will run a container with the default user/password of neo4j/neo4j. Visiting http://localhost:7474 will open a web based browser built into Neo4j. You will be asked to login and change the default password. This configuration does not persist any data between restarts of the container. The Neo4j docs have a section that talks about persistence if you want to take this example further.
Load an example movie graph
The code example linked in the resources uses data about movies that is easily loaded from the Neo4j data samples.
Issuing the :guide movie-graph command in a Neo4j query prompt will bring up a multistep tutorial. If you want to run the example code you only need to complete the steps to create the different nodes, establish relationships and build indexes. The rest of the tutorial is helpful as a high level example of what you can do with the Cypher query language.
You should get a graph of movies connected to people like the following:
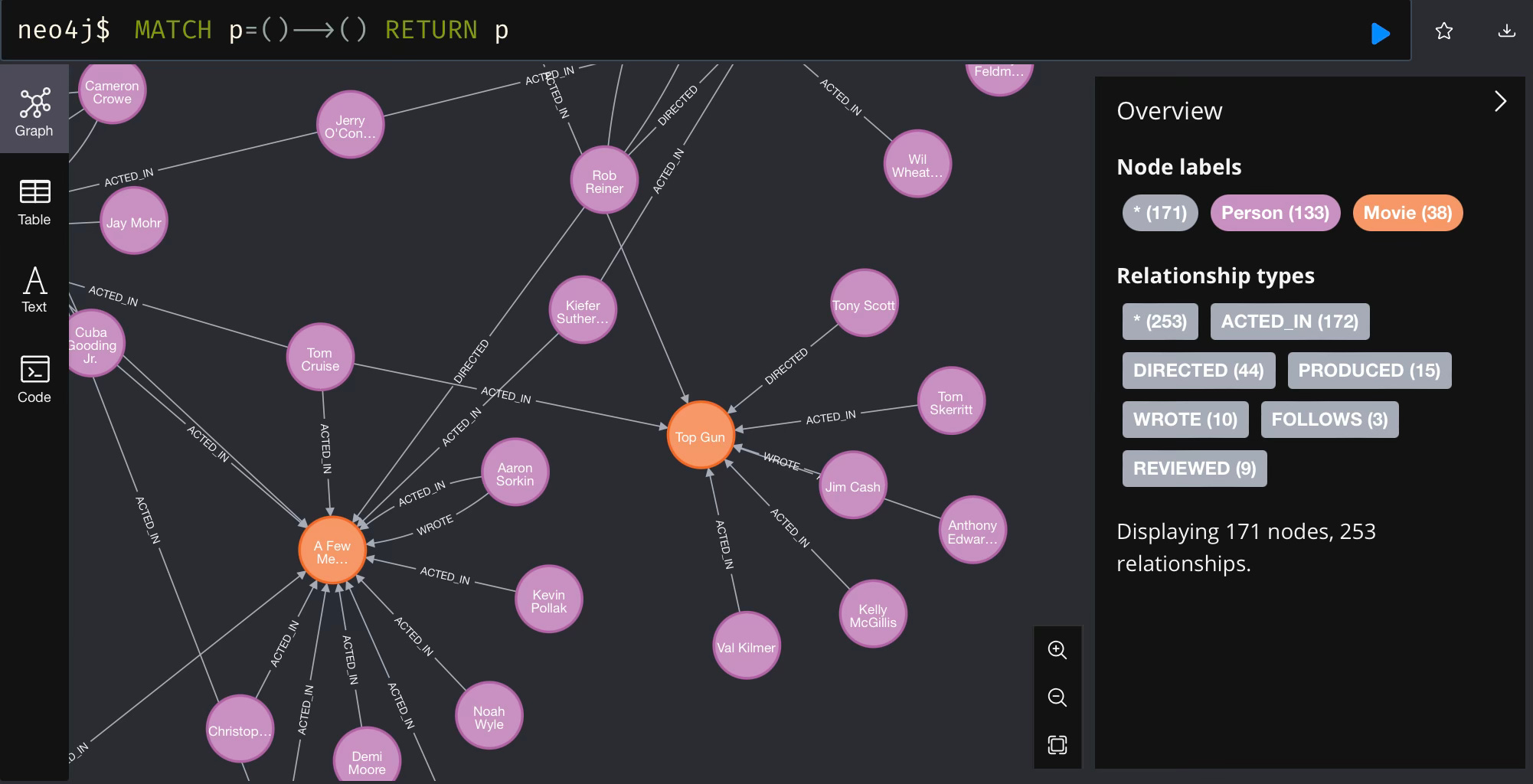
RAG with a graph
We can apply the retrieval augmented generation pattern in a similar way that we did in a previous article.
Retrieval Augmented Generation (RAG)

Retrieval Augmented Generation (RAG) is a technique where context is loaded from a datastore and a large language model is directed to work on the data provided.
One of the reasons we might want to retrieve information from graphs is graphs can convey information about how different items are related. A second reason is because a graph might have real time, dynamic data about a given domain. This information isn’t part of the original data used to train the large language model so the model is unlikely to give reasonable answers about specialized content without some context.
There are a few ways we can retrieve information from Neo4j graphs
Hand craft Cypher queries and call them through fixed pipelines or tool calling patterns
Use the graph schema and a large language model to dynamically generate cypher queries
Use vector search capabilities built into Neo4j to do semantic search on specially configured properties and indexes
We will focus on use case #2 where a large language model will generate Cypher queries based on the schema of the graph. The flow looks like the following steps:
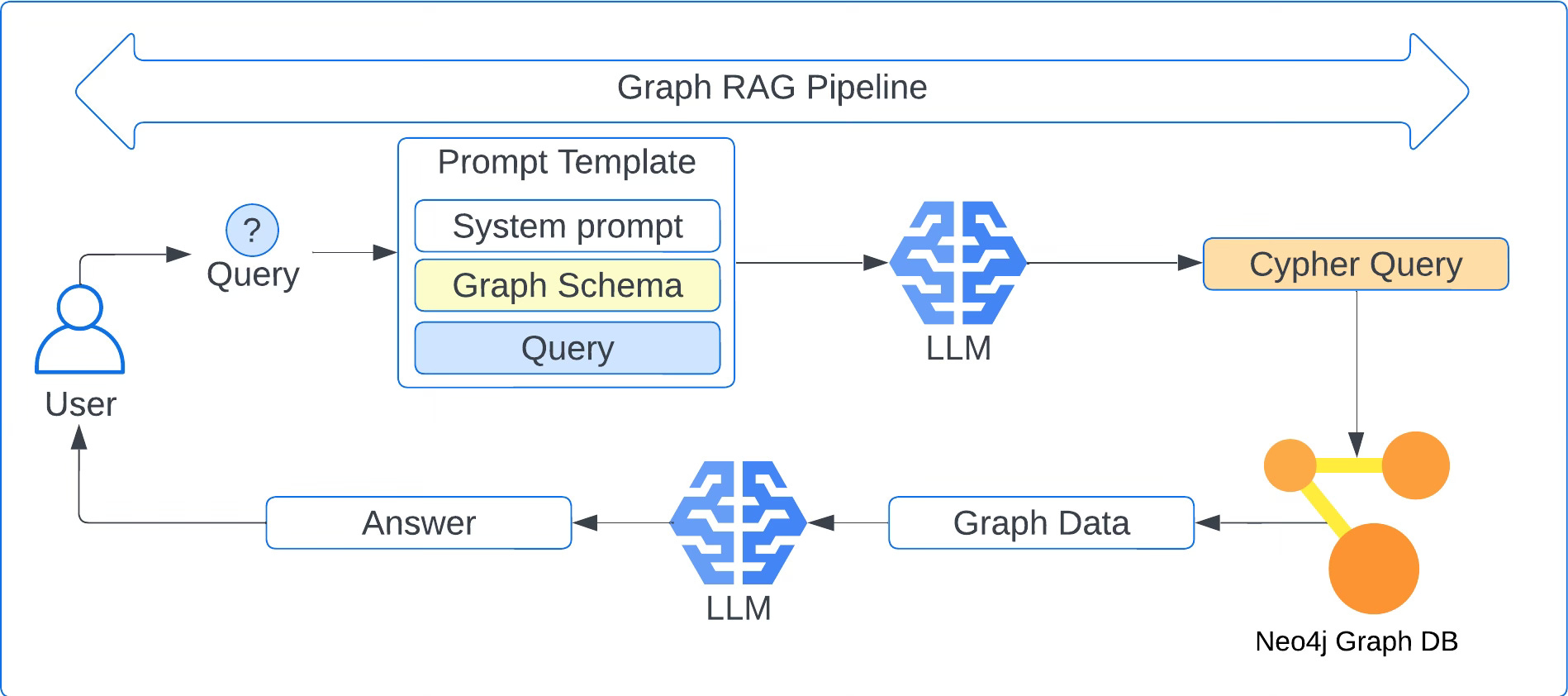
The user asks a natural language question.
The user’s question is combined with a system prompt and schema information about the graph.
This combined text is all passed into the context window for the model
The language model generates a relevant cypher query.
The resulting cypher query is passed into the Neo4j database
The graph query result is formatted by the language model into a natural language answer.
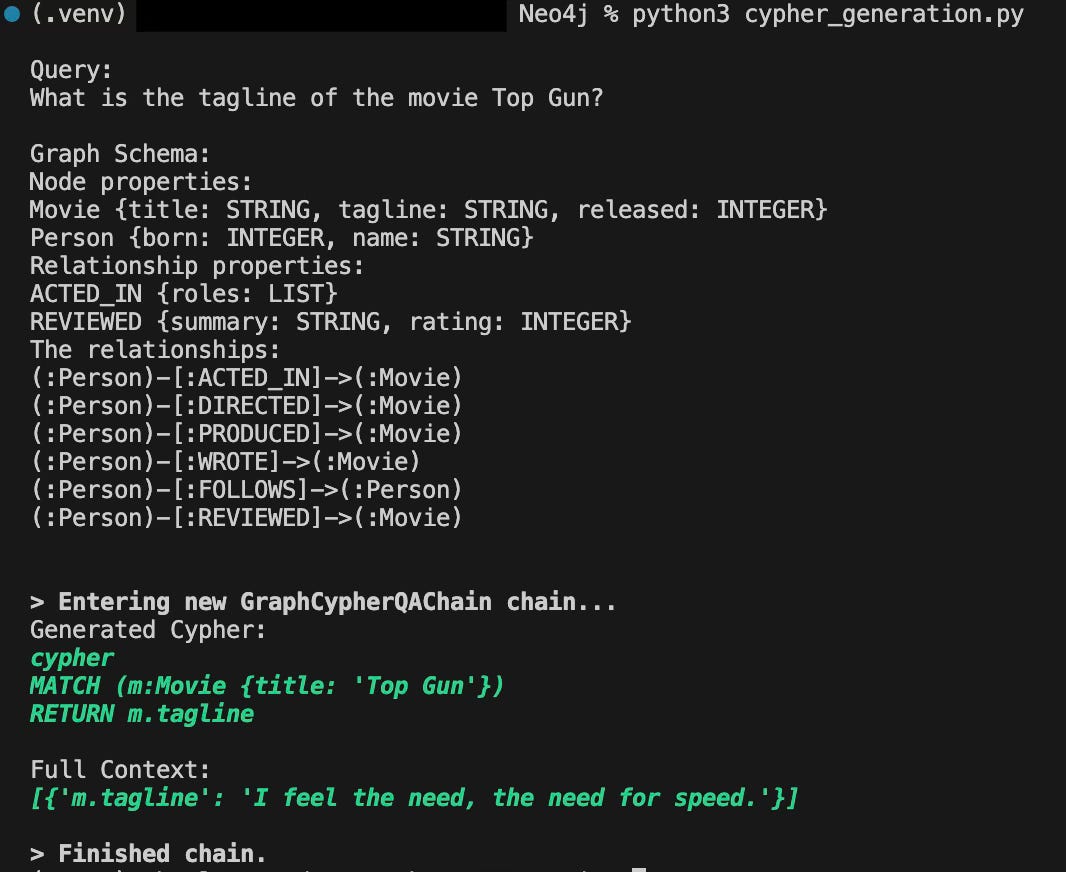
The full code for a LangChain based Q&A pipeline is linked in the Resources section. The output of this code shows the Cypher query the model generated and corresponding result from the database.
Strengths
There are several strengths with the dynamic query approach, which include:
Queries are always current
Dynamic graph data is rich with validated data
LLMs have many examples of Cypher queries in their training data
Queries are always current
Systems with databases are constantly dealing with drift between hard coded queries and the current schema of the database. Database and operations specialties have emerged to put processes in place to write, test and synchronize database changes. With this approach, the schema is pulled at the time of a user’s question and the query is based on that newest information.
Queries are always generated against the newest schema.
Dynamic graph data is rich with validated data
Data in a graph database can be updated in real time by other systems. These systems update the graph nodes and relationships using carefully crafted business rules. Both the timelines and correctness of this data can make this data highly valuable compared to general information found in internet based training data. Grounding the model with accurate data opens the door for many commercial applications.
Current and validated data has more commercial value.
LLMs have many examples of Cypher queries in their training data
Neo4j is a widely used graph database technology that was originally released in 2007. The Neo4j developer docs note that OpenAI, Anthropic and other companies offering state of the art language models include Cypher queries by virtue of including a large body of open source projects. Besides Cypher queries being included in the foundation model training data, Neo4j offers full featured SDKs and contributes packages to third party ecosystems like LangChain.
Weaknesses
The approach of dynamically generating queries has several weaknesses that include
Injection vulnerabilities
Invalid queries can be generated
Twice the LLM calls
Injection vulnerabilities
This approach is vulnerable to injection attacks. A malicious user could craft their question in such a way that the model might happily hand over data it shouldn’t. There is active research going on about prompt injection and while some useful patterns are emerging to safe guard data, the most fundamental mitigation for this weakness is just to operate on a read only copy of the database that has no sensitive data. Anything that needs to write to the database would need to pass through appropriate business logic like any other data from the outside world.
You can’t leak data if you don’t have it
Invalid queries can be generated
While there is a large body of training data for Cypher queries, LLMs are still non deterministic systems that can make mistakes. Mistakes can be amplified by factors such as ambiguity in a database schemas and very large database schemas. One technique to mitigate this weakness is to incorporate few-shot approaches where several examples are included with the other information provided to the model. Limiting the size of the schema is another solution path. This focused schema approach also has operational benefits such as fine grained resource tuning and faster maintenance times for tasks like rebuilding indexes and backup management.
Few-shot examples can produce better language model outcomes.
Twice the LLM calls
We have to use the LLM to generate the query and another call to summarize the results. Larger graphs and query responses can increase the number of input and output tokens consumed. In development environments the token load is nominal but production scale workloads with hundreds, thousands or even millions of calls can quickly become expensive. There are several mitigation approaches for this weakness.
One approach is to route tasks to smaller or otherwise cheaper models. For example, the simpler summarization of graph query results may be suitable for a smaller model. As we discussed in a recent article on small language models, capable small language models can be run on dedicated, lower cost compute nodes. This removes the back and forth billing of input/output tokens and replaces that variable with more predictable cloud spend. Cloud spend can be further reduced by reserving capacity or using excess compute that is often sold at a deep discount.
SmolLM2

One way language models have gained dramatic increases in capabilities, including emergent capabilities we can’t explain well, is by expanding into 10s of billions of parameters. These large models require several clustered GPUs or expensive server grade GPUs to operate. Training requires even more compute resources. The accompanying power bu…
Other ways to deal with the LLM call volume include caching techniques for generated queries and moving to hand crafted, templated queries once the data model is stable. Multiple approaches can also be employed such as checking a cache, then templated queries and finally LLM generated queries if no other solution is found.
Resources
ML Reference Designs (Code for this article)
Official Neo4j containers https://hub.docker.com/_/neo4j
Neo4j Docker documentation https://neo4j.com/docs/operations-manual/current/docker/
Neo4j online training at Graph Academy https://graphacademy.neo4j.com
LangChain Neo4j integration https://python.langchain.com/docs/integrations/graphs/neo4j_cypher/
OWASP LLM Top 10, prompt injection https://genai.owasp.org/llmrisk/llm01-prompt-injection/
Few-shot prompting https://www.promptingguide.ai/techniques/fewshot